Introduction
This is a comparison of a simple online demo photobook implemented with three popular java cloud ready framework :
Status : Work in progess
TODO:
-
benchmark chapter
-
performance comparison chapter
-
resources chapter
Copyright
@2024 Matteo Franci - CC BY 4.0 - ATTRIBUTION 4.0 INTERNATIONAL - https://creativecommons.org/licenses/by-nc-sa/4.0/deed.en
All trademarks, logos and brand names are the property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names,trademarks and brands does not imply endorsement.
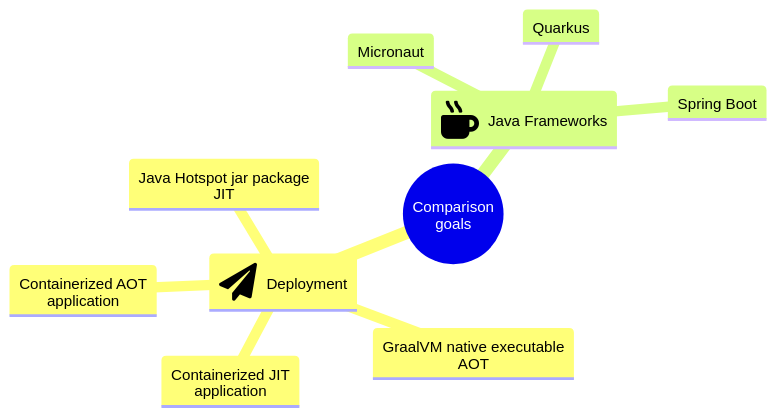
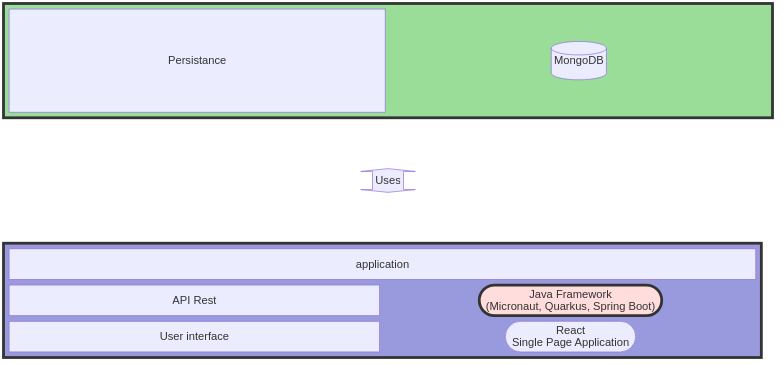
1. Architecture
This section describes the project architecture.
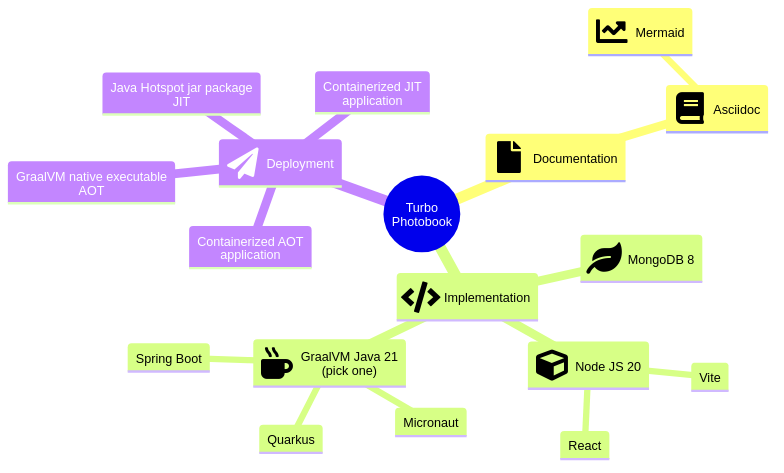
2. Implementation
Each implementation has its own repository :
| Framework | GitHub repository | Description |
|---|---|---|
A modern, jvm-based, full-stack framework for building modular, easily testable microservice and serverless applications. |
||
A Kubernetes Native Java stack tailored for OpenJDK HotSpot and GraalVM, crafted from the best of breed Java libraries and standards. |
||
Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can "just run". |
Each project structure is based on Maven Standard Directory Layout :
| path | description |
|---|---|
src/main/java |
Application (Micronaut / Quarkus / Spring Boot) sources |
src/main/resources |
Application (Micronaut / Quarkus / Spring Boot) resources |
src/main/react |
React front end sources |
src/test/java |
Test sources |
src/test/resources |
Test resources |
src/main/docker |
Dockerfile (JIT, native), docker-compose |
src/main/script |
Project scripts (simple benchmark and utilities) |
src/main/docs |
Project specific documentation assets |
README.md |
Readme |
CHANGELOG.md |
Changelog (keep a changelog style) |
LICENSE |
License |
CONTRIBUTING.md |
Contribution guide lines |
| Feature | Micronaut | Quarkus | Spring Boot |
|---|---|---|---|
Version |
4.5.x |
3.12.x |
3.3.x |
Java |
21 |
21 |
21 |
Virtual threads |
Yes |
Yes |
Yes |
HTTP 2 |
Yes |
Yes |
Yes |
Cache |
Caffeine |
Caffeine |
ConcurrentMap |
Native image |
GraalVM |
GraalVM |
GraalVM |
Containerized JIT |
Yes |
Yes |
Yes |
Containerized AOT |
Yes |
Yes |
Yes |
2.1. MongoDB collection definitions
Persistence layer is implemented through the no sql database MongoDB.
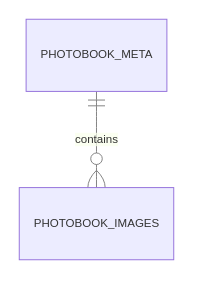
Here are two sample documents :
{
"photobookId":"springio23",
"creationTime:":{"$timestamp":{"t":0,"i":0}},
"modificationTime:":{"$timestamp":{"t":0,"i":0}},
"author":"Fugerit",
"labels": {
"def": {
"photobookTitle":"Spring I/O - Barcellona",
"photobookDescription":"Breve album sull'esperienza allo Spring I/O 2023 di Barcellona"
},
"en": {
"photobookTitle":"Spring I/O - Barcelona",
"photobookDescription":"Brief summary of my experience at the Barcelona Spring I/O 2023"
}
}
}{
"imageId":1000,
"photobookId":"springio23",
"creationTime:":{"$timestamp":{"t":0,"i":0}},
"modificationTime:":{"$timestamp":{"t":0,"i":0}},
"author":"Fugerit",
"base64":"...",
"type":"jpg",
"labels": {
"def": {
"caption":"Ingresso alla \"Fira de Barcelona\" per la registrazione."
},
"en": {
"caption":"Entrance to the \"Fira de Barcelona\" for registration."
}
}
}A example init script can be found on the GitHub project :
https://github.com/fugerit-org/turbo-photobook/blob/main/src/test/resources/mongo-db/mongo-init.js
2.2. MongoDB aggregation pipelines
Database queries are implemented though MongoDB Aggregation pipelines.
Aggregations pipelines allow to process a document in multiple steps (stages).
Here are the aggregations currently used :
-
List photobooks
Applied to collection 'photobook_meta', list the photobooks contained in the database with page handling.
It is composed of some stages :
-
set labels based on language
-
sort the collection result
-
project the properties for the result (_id is excluded)
-
facet with meta informations for page handling
[
{
$set:
{
info: {
$ifNull: ["$labels.en", "$labels.def"],
},
},
},
{
$sort:
{
photobookId: 1,
},
},
{
$project:
{
_id: 0,
photobookId: 1,
author: 1,
info: 1,
},
},
{
$facet:
{
metadata: [
{
$count: "total",
},
{
$addFields: {
page: NumberInt(1),
},
},
],
data: [
{
$skip: 0,
},
{
$limit: 10,
},
],
},
},
]-
List images in a photobook
Applied to collection 'photobook_images', list images contained in photobook with page handling.
It is composed of some stages :
-
match filter the selected photobook
-
sort the collection result
-
set labels based on language
-
project the properties for the result (_id is excluded, base64 is not included too)
-
facet with meta informations for page handling
[
{
$match: {
photobookId: "springio23",
},
},
{
$sort:
{
imageId: 1,
},
},
{
$set: {
info: {
$ifNull: ["$labels.en", "$labels.def"],
},
},
},
{
$project: {
_id:0,
imageId:1,
author:1,
type:1,
info:1
},
},
{
$facet: {
metadata: [
{
$count: "total",
},
{
$addFields: {
page: NumberInt(1),
},
},
],
data: [
{
$skip: 0,
},
{
$limit: 30,
},
],
},
},
]-
Image base64 content
Applied to collection 'photobook_images', retrieves only the base64 content for rendering.
It is composed of some stages :
-
match filter the selected image
-
project the properties for the result (only base64 content)
[
{
$match:
{
imageId: 1000,
photobookId: "springio23",
},
},
{
$project:
{
_id: 0,
base64: 1,
},
},
]